سلام
بحثی که توی شبکههای بازگشتی هست پیچیده تر از فقط مشکل گرادیان در تابع فعالسازی هستش
در حقیقت یه علت ساده دیگهای که مشکل vanishing یا exploding گرادیان پیش میاد، ضرب ماتریس وزنهای hidden hidden توی مرحله backprop ه
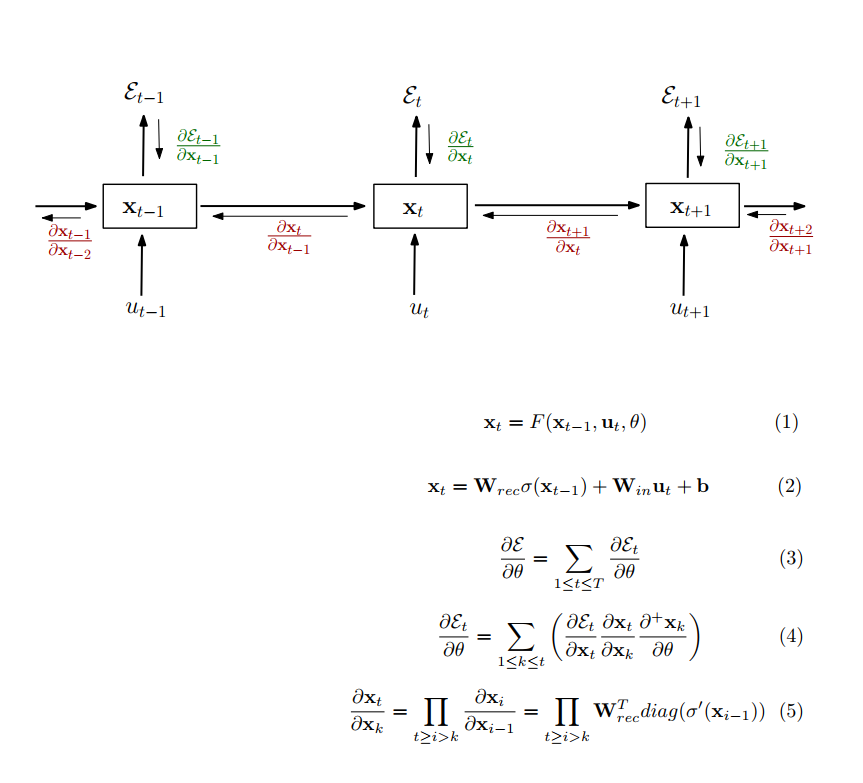
برای اطلاعات بیشتر و تحلیل دقیقتر می تونید این مقاله رو ببینید:
On the difficulty of training Recurrent Neural Networks
https://arxiv.org/abs/1211.5063
مقالات مرتبط با LSTM به خصوص مقاله اصلی و اولیش هم روی این موضوع خیلی بحث کرده، فصل 10 کتاب Deep learning هم اطلاعات خوبی در این زمینه داره
توی ساختارهای مثل خانواده LSTM یا clockwork، سعی میشه که با اضافه کردن مسیرهایی شبیه skip connection که توی resnet یا densenet وجود داره، مشکل vanishing gradient حل بشه . ساختارهای resnet و densenet که گفتم برای واضح تر شدن موضوعه وگرنه اینها خیلی بعد از lstm و مشکلات rnn ها مطرح شدند اما ایده هایی که موفق بوده در طول این مدت خیلی اشتراک دارند.
اما از اینا بگذریم حرف شما هم می تونه درست باشه و اتفاقا یه مقاله خیلی جالب در این زمینه هست که ایده کلیش اینه:
اگه یه شبکه عصبی داشته باشیم که از relu استفاده کنه و درست initializeش کنیم، می تونیم جواب خوبی بگیریم(حداقل روی یه سری از مسائل) که به عنوان IRNN مطرح شده
نحوه initilization وزنهاشم خیلی سادست(ماتریس همانی برای وزنهای hidden hidden)
A Simple Way to Initialize Recurrent Networks of Rectified Linear Units
https://arxiv.org/abs/1504.00941
توی نتایج این مقاله نشون داده شده که یه initialization خوب، توی همون RNN معمولی، می تونه کارکردی شبیه ساختارهای پیچیده تر مثل LSTM داشته باشه و در بعضی از مسائلش حتی بهتر عمل کنه
البته اینو باید در نظر داشته باشید که شاید مقایسه هایی که اتفاق افتاده خیلی عادلانه نباشه که توی مقاله هم سر بسته بهش اشاره شده اما به هر حال نکته خیلی مهمی رو نشون داده