سلام
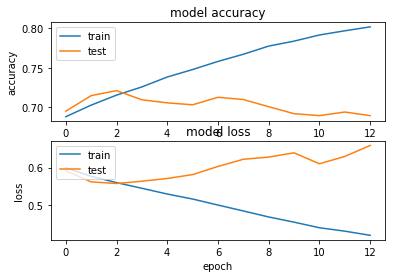
شبکه فقط دو اپوچ بهبود پیدا میکنه و بعد over-fit میشه
optimizer = nadam , LR=0.001
با مقادیر 0.1 0.001 0.0001 هم تست کردم همه رو دو سه اپوچ اول اورفیت میشن
1- راه های جلوگیری از این قضیه چیه ؟
2- reqularization رو کجا اعمال کنیم بهتره و به چه شکل ؟
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(width, height,1)))
model.add(Activation('relu'))
#model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))#3
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
#model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))#3
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
#model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))#3
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
#model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))#3
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(64))
#model.add(BatchNormalization())
model.add(Activation('relu'))
#model.add(BatchNormalization())
model.add(Dropout(0.7))
model.add(Dense(1))
model.add(Activation('sigmoid'))
sgd = keras.optimizers.Nadam(lr=0.001)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
keras.callbacks.Callback()
from keras.callbacks import ModelCheckpoint
from keras.callbacks import EarlyStopping
model_path = 'd:\\fm_cnn_BN.h5'
# prepare callbacks
callbackss=[ EarlyStopping(
monitor='val_acc',
patience=10,
mode='max',
verbose=1),
ModelCheckpoint(model_path,
monitor='val_acc',
save_best_only=True,
mode='max',
verbose=1)]
history=model.fit_generator(
train_generator,
steps_per_epoch=int(train_generator.samples/train_generator.batch_size), #x_train.shape[0] // batch_size,
epochs=100,
validation_data=validation_generator,
validation_steps=int(validation_generator.samples/validation_generator.batch_size),
callbacks=callbackss
)
#model.save_weights('d:\\fm_cnn_BN2.h5') # always save your weights after training or during training
print('test result')
model.load_weights('d:\\fm_cnn_BN.h5') # always save your weights after training or during training
score=model.evaluate_generator(test_generator,steps=int(test_generator.samples/test_generator.batch_size))