سلام دوستان. من قبلا هم در مورد این معماری اینجا سوال پرسیدم و دوستان هم لطف کردن و جوابای بجایی دادن(تشکر از لطفشون) منم خود مقاله اصلیش رو خوندم و از جواب دوستان و مطالب مقاله تقریبا میدونم چجوره ولی هنوز کامل واسم جا نیفتاده
برا همین من برداشتمو از این موضوع میگم لطفا اگه اشتباه و ناقص بود اصلاح بفرمایید
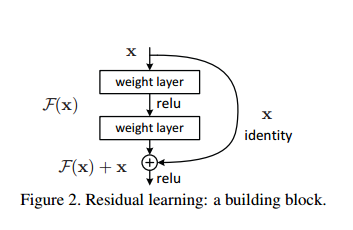
1- ما انتظار داریم وقتی عمیق یک شبکه رو افزایش میدیم دقتش افزایش پیدا کنه....... واسه همین مقاله فوق میاد دو تا شبکه با معماری یکسان که یکیشون از اون یکی عمیق تره رو آموزش میده و تست میکنه..... ولی برخلاف انتظار خطای شبکه عمیق تر از خطای شبکه کم عمق بیشتره..... و لایه هایی که به شبکه اضافه شدن مثل تابع همانی عمل می کنند(یعنی همونی که به عنوان ورودی می گیرن رو میدن به خروجی)....(یعنی چیز جدیدی تولید نکردن)......حالا مقاله میاد ایده میده که این لایه ها به جای یاد گرفتن تابع همانی تابع 0=(x)f رو یاد بگیرن و از طریق یه میان بر ورودی رو میده به خروجی بلوک(که باز همون تابع همانی تولید میشه) و میگه شبکه این تابع رو بهتر یاد میگره
حالا سوال من اینه....... اگه این لایه ها مثل تابع همانی عمل میکنن(یعنی هرچی میاد به ورودی همون رو میدن به خروجی) دیگه چه لزومی داره توی معماری قرارشون بدیم....ولی از اون طرف تو نتایج می بینیم که مفید هستن(آیا فقط واسه این هست که گرادیان بهتر پارامترها رو بروز رسانی کنه)
سوال بعدم اینکه گفته شبکه راحت تر می تونه تابع F(x)+x و بهینه کنه تا تابع همانی رو..... این چجوره؟
من برداشتم اینه که چیزی که باعث افزایش دقت این شبکه ها شده افزایش عمقشون نیست بلکه نوع معماریه که ارایه دادن(و توی این معماری گرادیان راحت تر می تونه وزن ها رو بروزرسانی کنه)
ممنون میشم راهنمایی بفرمایید.... نکات تاریک موضوع واسم روشن بشه