سلام
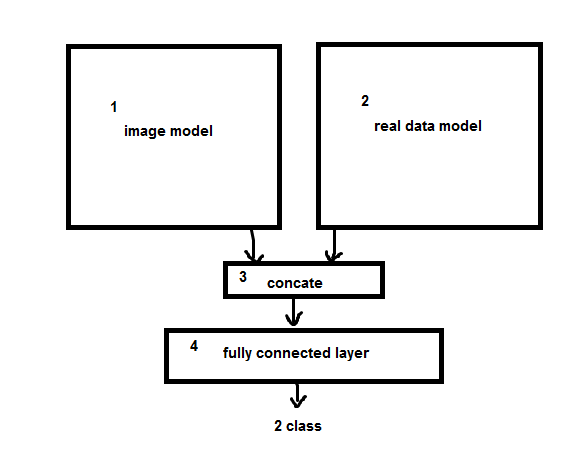
دو مدل جدا داشتم
مدلی برای تصویر به تنهایی 84 درصد صحت داشت و مدل داده به تنهایی 82 درصد صحت داشت ولی ترکیبشون که تو تصویر اومده 70 درصد صحت میده !
هر دو مدل رو با هم آموزش دادم و بعد ترکیب کردم و دادم به لایه ی fully connected(لایه ی fc عوض نشد و همونی که تو مدل تکی بود استفاده کردم)
ولی نمیدونم چرا صحت انقدر کم شد !
راه حل ممکن که به ذهنم میرسه:
1- اول مدل 1 رو آموزش بدم و مدل 2 رو trainable رو غیر فعال کنم و بعد مدل 1 رو trainable رو غیر فعال کنم و مدل 2 رو آموزش بدم و بعد هر دو غیر فعال کنم و لایه ی FC رو آموزش بدم
2- اول مدل 1 رو آموزش بدم و مدل 2 رو trainable رو غیر فعال کنم و بعد مدل 1 رو trainable رو غیر فعال کنم و مدل 2 رو آموزش بدم
3- همین راهی که رفتم درسته و هر دو مدل رو همزمان آموزش بدم ولی یه جای کارم اشکال داشته که صحت کمتر شده
نظر شما چیه ؟
4- دو مدل رو کلا جدا آموزش بدم(ترکیب نباشه) بعد بیام وزن هارو انتقال بدم به شبکه ی جدید و trainable =false کنم؟
5- تو فاز آموزش هر 5 اپوچ جواب بهتر میشه(5 تا acc کاهش پیدا میکنه یکجا میزنه بهتر میشه) به نظرتون با Batch norm بهتر بشه ؟ کجاش batch norm قرار بدم بهتره ؟
کدوم راه ها درست هست ؟ و کدوم درست تر ؟!
import keras
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
from tqdm import tqdm # a nice pretty percentage bar for tasks. Thanks to viewer Daniel Bأ¼hler for this suggestion
import os # dealing with directories
#import cv2 # working with, mainly resizing, images
import numpy as np # dealing with arrays
from random import shuffle # mixing up or currently ordered data that might lead our network astray in training.
import matplotlib.pyplot as plt
#plt.imshow(img)
from keras import regularizers
from keras.models import Sequential,Model
from keras.layers import Conv2D, MaxPooling2D,BatchNormalization,Conv3D
from keras.layers import Activation, Dropout, Flatten, Dense,TimeDistributed,Bidirectional,LSTM,Reshape
# Model
#img <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
input1 = keras.layers.Input(shape=(300, 800,1))
conv1= Conv2D(filters=4,kernel_size=(5,5),strides=(3,3), activation='relu',name='img_conv1')(input1)
max1= MaxPooling2D(2,1,name='img_max1')(conv1)
drop1= Dropout(0.25,name='img_drop1')(max1)
conv2= Conv2D(filters=8,kernel_size=(5,5),strides=(3,3), activation='relu',name='img_conv2')(drop1)
max2= MaxPooling2D(2,1,name='img_max2')(conv2)
drop2= Dropout(0.25,name='img_drop2')(max2)
flat1=Flatten(name='img_flat1')(drop2)
#>>>>>>>>>>>>>
# data
input2 = keras.layers.Input(shape=(16410,))
m2_dense1= Dense(128,kernel_initializer='lecun_uniform', activation='relu')(input2) # kernel_regularizer=regularizers.l2(0.01)
m2_drop1= Dropout(0.5)(m2_dense1)
m2_dense2= Dense(64,kernel_initializer='lecun_uniform', activation='relu')(m2_drop1)
m2_drop2= Dropout(0.5)(m2_dense2)
#m2_dense3= Dense(8,kernel_initializer='lecun_uniform', activation='relu')(m2_drop2)
#m2_drop3= Dropout(0.5)(m2_dense3)
#flat=Flatten()(m2_drop2)
#############
flat=keras.layers.concatenate([flat1,m2_drop2], axis=-1)
#flat=Flatten()(merg)
fc_dense1= Dense(256, activation='relu', kernel_regularizer = regularizers.l2(0.001))(flat)
fc_drop1= Dropout(0.96)(fc_dense1)
fc_dense2= Dense(8, activation='relu', kernel_regularizer = regularizers.l2(0.001))(fc_drop1)
fc_drop2= Dropout(0.7)(fc_dense2)
out=Dense(1,activation='sigmoid')(fc_drop2)
model = keras.models.Model(inputs=[input1,input2], outputs=out)
sgd = keras.optimizers.Nadam(lr=0.0001)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
با تشکر