قبلاً کمی درباره ایده کلی در سوال زیر نوشتم :
http://qa.deeplearning.ir/3710/تفاوت-بین-لایه-های-pooling-و-strided-convolution
در حال پیاده سازی کد مقاله برای شفاف شدن جزییات مقاله برای خودم هستم اما نمیدونم تا کی بتونم تکمیلش کنم از طرفی کلی مشق سرمون ریختن ، از علوم شروع کن تا ، ریاضی و ادبیات و ... :( ) مطالبی که به ذهنم میرسه رو براتون مینویسم و سعی میکنم به زودی پاسخ رو کامل تر کنم.
قبل از هر چیز من میگم آقای هینتون قبل از اینکه متخصص هوش مصنوعی باشند یه دانشمند علوم شناختی هستند.
یک واقعیت جالب که توجه آقای هینتون رو به خودش جلب کرد مطالعات اخیر نوروآناتومی هست که ، خبر از حضور تعداد زیادی لایه در قشری از مغز (بیشتر پستانداران) به نام Minicolumn Cortical میده که ساختار ستون مانند (cortical micro-column) دارند و هر کدوم حاوی صدها نورون هستند . این به این معنی است که یک لایه در مغز انسان شبیه به لایه های فعلی در یک شبکه عصبی نیست، بلکه دارای یک ساختار داخلی پیچیده است. برای جزییات بیشتر میتونید به مقاله با عنوان فرضیه minicolumn در علوم شناختی مراجعه کنید.

هر چند آقای هینتون پذیرفتند که شبکه های عصبی کانولوشن خیلی خوب عمل میکنند اما یک سری آزمایشات در علوم شناختی انجام دادند که در میان اونها آزمایش tetrahedron puzzle ایشون رو متقاعد کرد که شبکه های کانولوشن بااینکه خوب عمل میکنند اما مشکلات عدیده ای دارند. من وارد جزییات این آزمایش نمیشم اما قبل از مشاهده راه حل سعی کنید خودتون این مسیله خیلی ساده رو حل کنید.
جزییات بیشتر در لکچر ایشان
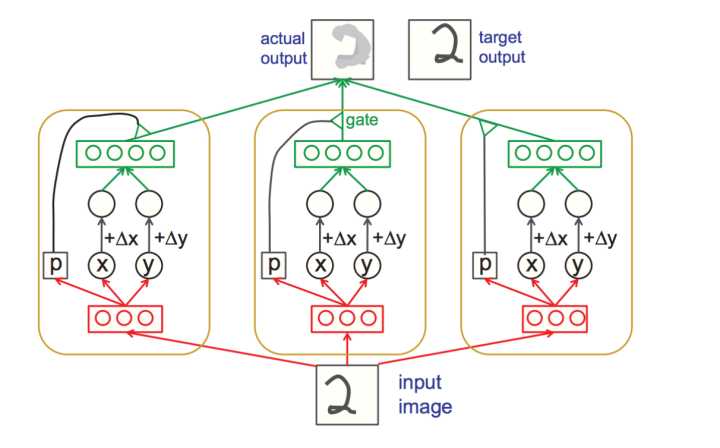
ایده capsule در واقع قصد داره مشکل maxpooling در ساختار کنونی شبکه های کانولوشن رو حل کنه. Maxpooling مشکل تغیرات (invariance) موقعیتی رو تا حدودی حل میکنه و از دیدگاه بازشناسایی عکس یک مورد خیلی خوب هست اما با دانش ما از مورفولوژی زیاد سازگار نیست.
Capsnet از سه لایه تشکیل شده که به ترتیب Conv1 ، PrimaryCaps و DigitCaps نام دارند.
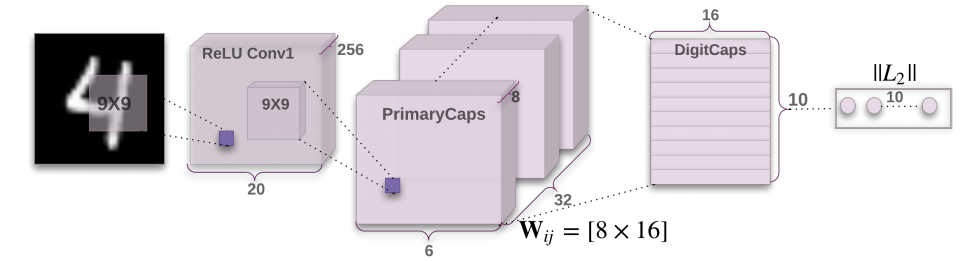
Conv1 در واقع یک لایه کانولوشن معمولی دو بعدی با فیلتر های 9*9 ، طول گام 2،عمق 256 و تابع فعال ساز Relu .با توجه به مقاله نقش اصلی این لایه انجام استخراج ویژگی های لوکال از پیکسل های تصاویر ورودی و انتقال اونها به کپسول هست . دلیل اینکه چرا در لایه اول از کپسول برای استخراج ویژگی ها استفاده نمیشه رو دقیقا نمیدونم، شاید دلیلش این باشه که کپسول قابلیت عمومی لایه کانولوشن که تشخیص ویژگی های لوکال هست رو نداره یا به دلیل قابلیت بسیار خوب لایه کانولوشن در استخراج ویژگی های سطح پایین هست ؟ :(
کپسول ها در لایه دوم با عنوان PrimaryCaps شناخته میشوند که منو یاد قشر اولیه بینایی یا Primary visual cortex میندازه( لایه کانولوشن اول همانند شبکیه چشم باشه لایه کانولوشن بعدی معادل قشر اولیه بینایی هست)
لایه PrimaryCaps از 32 واحد کپسول تشکیل شده که هر کدوم از این واحد ها خروجی لایه Conv1 که یک تنسور ویژگی با ابعاد [256, 20, 20] (به غیر از اندازه batch) رو دریافت و یک عملیات کانولوشن دو بعدی بر روی این تنسور انجام میده که اندازه فیلتر 9 در 9 و طول گام 2 هست که خروجی با ابعاد [8, 6, 6] رو تولید میکنه. به عبارتی شما میتونید این 32به اصطلاح کپسول به عنوان 32 لایه کانولوشن دو بعدی موازی در نظر بگیرید.در انتها خروجی این 32 کپسول با هم الحاق میشن به یک بردار [1152, 8] تغییر شکل داده و به لایه بعدی که DigitCaps باشه انتقال داده میشوند.
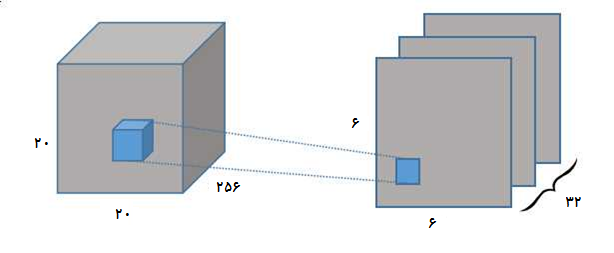
البته خروجیهای لایه PrimaryCaps قبل از انتقال به لایه بعد فشرده میشوند. در این معماری از تابع Squash به عنوان تابع فعال ساز استفاده میشه که میتونیم اون رو مثل تابع سیگمید در نظر بگیریم . بر خلاف شبکه های عصبی تماما متصل که تایع فعال ساز بر روی هر کدام از مقادیر خروجی نرون ها(مقادیر اسکالر) اعمال میشه در این معماری بر روی کل بردار اعمال میشه. (شکل تابع در بخش دوم مقاله معادله 1 آورده شده).
لایه DigitCaps از 10 کپسول 16 بعدی تشکیل شده. اگه بخوایم این لایه رو با یک لایه تماما متصل در شبکه های معمولی با نرون های اسکالر مقایسه کنیم ، لایه DigitCaps رو میتونید به عنوان یک شبکه عصبی تماما متصل با خروجی از نرون های 16 بعدی در نظر بگیرید که این نرون ها رو کپسول مینامیم. در این لایه ورودی [1152, 8] در یافت میشه و به 10 کپسول ارسال میشه.
در مورد مسیر یابی پویا هنوز در حال ایجاد دیاگرام های مربوطه هستم. جزییات هر کدوم از بخش ها رو سعی میکنم در ویرایش بعد قرار بدم.
این ایده هنوز جای کار بسیار زیادی داره.اگه توجه کرده باشین در این مقاله از پایگاه داده MNIST استفاده شد.آموزش معماریی از این دست بر روی پایگاه داده Imagenet با توجه به سناریوی کنونی غیر ممکن است.