ابتدا بایستی این نکته رو بگم که لایه تماما متصل دقیقا معادل یک لایه کانولوشن با اندازه فیلتر ۱×۱ هست .
خروجی لایه های کانولوشن نشان دهنده ویژگی های سطح بالا در داده ها هست ، به عبارت ساده هدف لایه های کانولوشن در پردازش عکس ساختن ویژگی ها از داده های خام هست ، اونها به دنبال اشیا موجود در عکس میکردند اما هیچ تصمیم گیری در مورد طبقه بندی انجام نمیدن . فلت کردن این ویژگی ها در انتهای شبکه و اتصال آنها به یکی دو لایه تماما متصل معمولا یک روش ارزان «از لحاظ بار محاسباتی» برای یادگیری ترکیبات غیر خطی این ویژگی ها هست .
ایده تبدیل لایه عایق تماما متصل به لایه کانولوشن شاید برای اولین بار در مقاله NIN مطرح شد . در معماری VGG تعداد پارامتر ها 133 میلیون است که بیش از 90 درصد این پارامتر ها در دو لایه تماما متصل این مدل قرار گرفته اند . این لایه ها عموما باعث بیش بر ارزش شدن شبکه میشوند . در NIN، Min Lin و همکارانش به جای استفاده از لایه های سنتی تماما متصل لایه از global average pooling استفاده کردند.
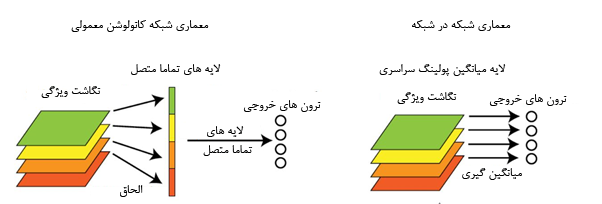
در این مقاله به جای استفاده از لایه تماما متصل سنتی آنها روشی به نام global average pooling را پیشنهاد دادند ، در شبکه هایی که از لایه تماما متصل برای کلاسهای بندی استفاده میکنند خروجی feature maps بعد از الحاق به یکدیگر به sofmax داده میشوند اما در این روش به ازای هر کلاس یک feature map بعد از آخرین لایه mlpcov تولید میشود به جای اضافه کردن یک لایه تماما متصل در بالای feature map ها آنها از feature map ها سود میبرند و نتایج بردار ویژگی مستقیما به softmax داده میشوند . یکی از ویژگی هایش این لایه نبودن مشکل بیش بر ارزش به علت عدم وجود پارامتری برای بهینه سازی است و از طرفی این لایه نسبت به تغییرات محلی مقاوم تر و با اصل شبکه هایش کانولوشن سازگارتر است.
قبلاً در این لینک توضیحات دادم :
بایستی گفت تنها تفاوت بین یک لایه تماما متصل و لایه کانولوشن اسپارسیتی کانکشن ها و اشتراک پارامترهاست ، هر چند نرون ها در هر دو لایه ضرب نقطهای رو محاسبه میکنند ، پس فرم تابعی اونها یکسان هست .
جزییات بیشتر :