سلام
1) بله، منظور atrous convolution هست
2) هنگام data augmentation که می خوان تعداد sample ها رو زیاد کنن، یه حالت اینه که بیان و از یه جای تصویر به صورت رندم و کورکورانه یه patch انتخاب کنن، اما حالت دیگه اینه که فقط patch هایی رو انتخاب کنن که یه overlapی با یکی از اشیا داخل تصویر داشته باشه.
حالا اینکه چقدر overlap داشته باشه رو گفته patch هایی رو انتخاب می کنیم که اگه معیار jaccard رو بین patch انتخاب شده با ground truth شی حساب کنیم بشه یکی از این اعداد
معیار jaccard خیلی مشابه dice یا f1 score ه که برای شباهت یا overlap دو تا ماسک توی segmentation یا توی detection استفاده میشه
https://en.wikipedia.org/wiki/Jaccard_index
3) نه اینکه حتما مرکز gt داخل patch باشه اما میگه اگه مرکز باکس داخل patch ی که به صورت رندوم تولید کردیم بود، نگهش می داریم. یه به عبارت دیگه یه جورایی داره می گه که اگه patch مون به اندازه کافی از gt داشت، اطلاعاتی از gt رو نگه می داریم و اگه overlapشون کم بود بی خیالش می شیم. یعنی اینطوری نیست که مثلا یه patch انتخاب کنیم، بعد یه گوشه کوچیک شی توش باشه و انتظار داشته باشیم شبکه بگه آهان ببین اون گوشه فلان object هم اینجاس
در مورد قسمت آخر سوالتون خیلی متوجه نشدم منظورتون چیه. الان فرض کنید که یه گربه توی تصویر بوده و ما توی sample کردن، یه patch گرفتیم که نصف گربه توش هست و چون وسط gt هم داخل patch بوده بر فرض، انتظار داریم که شبکه بتونه گربه رو تشخیص بده و box رو هم براش مشخص کنه. یعنی اونقدری که از gt توی تصویر بوده رو براش یه box در بیاره.
توی حساب کردن loss هم ما فقط پیش بینی شبکه رو با همون مقداری از gt که توی patch بوده حساب می کنیم
برای روشن تر شدن موضوع یه نقاشی توی paint هم آماده کردم :)))
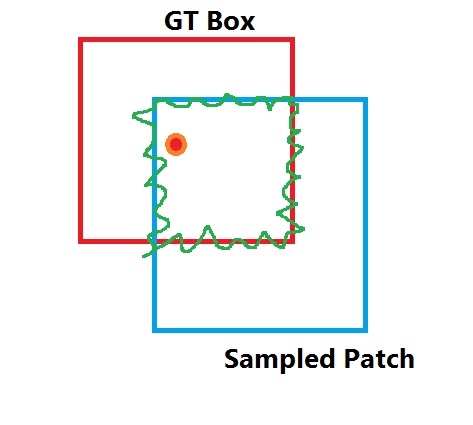
اون قسمت قرمز gt box که نشونگر box دقیق از شی هست و آبی چیزی هست که به صورت رندوم sample کردیم. حالا چون مرکز gt box داخل box آبی هست، پس اطلاعات gt box رو هم می خوایم نگه داریم و اون قسمت سبز رنگ که علامت زدم رو نگه می داریم و برای این patch آبی رنگ که انتخاب کردیم، انتظار داریم اون قسمت سبز رنگ به عنوان مکان شی پیش بینی بشه
حالا نمی دونم منظور شما همین بود یا نه. اگه نه لطفا بیشتر در مورد قسمت آخر توضیح بدید