شاید اولین دفعه ای که تصمیم گرفتم با deep reinforcement learning کمی دست و پنجه نرم کنم ، چند ماه پیش بود. توی گروه بچه های دبیرستانمون یه سری بازی بود که بچه های گروه همیشه انجام میدادند ، یکی از این بازی ها Mr.muscle بود (تلگرام). هر چند بازی کردن برای امتیاز گرفتن اتلاف وقت بود اما به این فکر افتادم که با استفاده از یادگیری عمیق الگوریتمی رو بنویسم که این بازی رو به صورت خودکار انجام بده و برام امتیاز بگیره :D
بعد از کمی جستجو به پست آقای karpathy برخوردم که برام خیلی جالب بود.
در این اینجا هدف من توضیح استراتژی بازی یا الگوریتمی که من برای بردن بازی استفاده کردم نیست ، اما سعی دارم به صورت خلاصه توضیحاتی در مورد reinforcement learning و منابع مفیدی که احتمالا شما باهاشون آشنایی دارید، بدم. به عنوان مثال شاید شما با کورس deep reinforcement
Learninglearning دانشگاه بروکلین که سال گذشته برگزار شد و تمامی جلسات به صورت زنده در یوتیوب قرار گرفت، آشنا باشید که منبع اصلی خیلی از افراد برای یادگیری این شاخه از یادگیری ماشینی است.
Deep reinforcement learning اخیرا خیلی مورد توجه محققین داده قرار گرفته است ، به عنوان مثال سال گذشته از این شاخه یادگیری ماشینی برای ایجاد الگوریتمی استفاده شد که توانست قهرمان جهان را در بازی Go شکست دهد یا الگوریتم های که بازی های Atari را بدون هیچ ناظری انجام میدادند .
در یکی دو قرن اخیر محققین علوم کامپیوتر همیشه به دنبال ساخت ماشین هوشمندی بودند که بتواند دنیای اطراف خودش را درک کند و با توجه به اون ادراک تصمیم صحیح را همانند انسانها بگیرد.
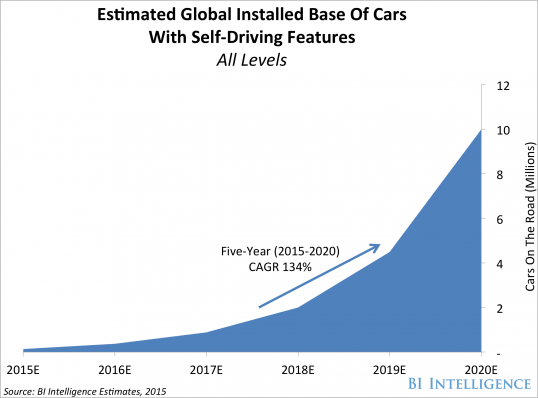
در دهه اخیر سرعت پیشرفت هوش مصنوعی به علت توجه ویژه محققین آکادمیک و صنعت و سرمایه گذاری شرکت های بزرگ دنیا افزایش چشمگیری پیدا کرده است و انتظار میرود رشد این پیشرفت ها همینطور ادامه پیدا کنند ، به عنوان مثال پیش بینی میشود تا سال ۲۰۲۰ ، ۱۰ میلیون خودرو راننده خودکار در سطح دنیا خواهیم داشت
چند ماه پیش که کورس deep reinforcement learning دانشگاه بروکلین برگزار شد برای من مطالب چند جلسه اول قابل فهم بود اما به مرور زمان که مباحث پیشرفته تر مورد بررسی قرار گرفت مفهوم آنها سخت تر شد به طوری که در میانه راه از دنبال کردن جلسات صرفنظر کردم.بعد از کمی تحقیق به کورس آقای دیوید سیلور
و کتاب یادگیری تقویتی آقای Richard S. Sutton برخوردم . این کورس وکتاب برای افرادی که آشنایی قبلی بر مباحثی مثل زنجیره های مارکوف و dynamic programing ندارید بسیار عالی هست! این کتاب حاصل تلاش ۳ دهه این دو محقق است .
در حال حاضر من تا میانه کتاب و کورس پیش رفتم ، و مباحث جالبی تا کنون مورد بحث قرار گرفته شده است . پیشنهاد میکنم این کورس رو دنبال کنید .در ادامه به صورت خلاصه مقداری در مورد یادگیری تقویتی مینویسم امیدوارم به کارتون بیاد.
اما کمی مقدمه Reinforcement learning چیه؟
Reinforcement learning یک شاخه از یادگیری ماشینی است بطوریکه یک عامل (agent) وجود دارد که با محیط (environment ) در ارتباط است. این عامل میتواند حالت های مختلف محیط (states) را مشاهده کنید و با توجه به حالت محیط یک عمل (action) را انجام دهد.هنگامی که یک عمل به اتمام میرسد حالت محیط تغییر میکند و عامل با توجه به تصمیمی که گرفته یک جایزه (reward) ( که میتواند منفی یا مثبت باشد) دریافت میکند.هدف این فرآیند ساخت عاملی است که از تجربیات خود ( که عمدتاً در ارتباط با محیط بدست میاید) یاد بگیرد، و تصمیمی را اتخاذ میکند که مجموع reward هایی از محیط دریافت میکند، بیشینه شود.
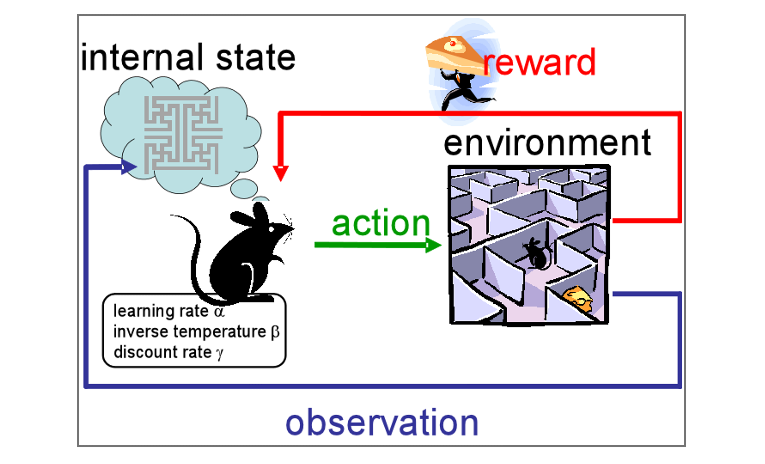
در یک سیستم بیولوژیکی reward میتواند همانند تجربه درد و لذت باشد . Reinforcement learning نسبت به یادگیری با نظارت و بدون نظارت متفاوت است . در یادگیری با نظارت ما داده های برچسب داری داریم که از این داده ها برای آموزش الگوریتمان استفاده میکنیم ، اما در یک مسیله تعاملی اغلب فراهم کردن نمونه های آموزشی از رفتار مورد نظرمان، رفتاری که عامل بایستی بر اساس آنها عمل کند،امکان پذیر نیست .در یک قلمرو ناشناخته عامل بایستی بتواند از تجربیاتی که در طی تعامل با محیط بدست میآورد ، یاد بگیرد .همچنین در یادگیری بدون نظارت هدف ما پیدا کردن یک ساختار پنهان در یک مجموعه دادگان بدون برچسب است . شاید برخی از افراد یادگیری تقویتی را متعلق به یادگیری بدون نظارت بدانند، بدین دلیل که یادگیری بدون نظارت به داده های برچسب دار وابسته نیست،اما در یادگیری تقویتی هدف بیشینه کردن سیگنال reward است، نه پیدا کردن ساختار پنهان داده ها( یا حداقل این مورد به تنهایی نمیتواند تمام مشکلات یک عامل را برای بیشینه کردن سیگنال reward حل کند). از این رو یادگیری تقویتی در کنار یادگیری با نظارت و بدون نظارت در گروه سوم پارادایمهای یادگیری ماشینی قرار میگرید.
یادگیری تقویتی به هیچ وجه یک زمینه تحقیقاتی جدیدی نیست، در حقیقت بیشتر متدهای موجود در یادگیری تقویتی که امروزه از آنها استفاده میشوند، چند دهه پیش کشف شدند ، اما امروزه به علت ترکیب آن با یادگیری عمیق و به لطف بالارفتن توان محاسباتی سیستم های کامپیوتری مورد توجه ویژه محققیق قرار گرفته اند.
یک مثال از یادگیری تقویتی بازی شطرنج است، در این بازی محیط همان تخته شطرنج ( مهره ها و موقعیت قرار گیری آنها) و عامل، برنامه کامپیوتری است که بازی را انجام میدهد . عامل حالت محیط را مشاهده میکند و مطابق با آن یک حرکت را انجام میدهد ، بعد از اتمام این حرکت شرایط محیط عوض میشود این چرخه ادامه پیدا میکند تا زمانی که بازی به پایان میرسد در نهایت عامل با توجه به برد و باخت یک امتیاز دریافت میکند . یادگیری تقویتی در اینجا میتواند توسط عامل برای بهتر کردن مهارت بازیش استفاده شود بطوریکه عامل در ابتدا به صورت خیلی ضعیف بازی میکند اما بعد از انجام تعداد زیادی راند، عامل میتواند یاد بگیرد که چه حرکت هایی را انتخاب کند تا در بازی برنده شود.
در یادگیری تقویتی، عامل در ابتدا نمیداند آیا حرکتی که انجام میدهد منجر به پیروزی و یا شکست آن میشود اما این عامل بایستی با انتخاب تصادفی حرکات و به حافظه سپردن نتیجه حرکت های انجام شده به کاوش (exploration)ادامه دهد.این کاوش ها به عامل این امکان را میدهد که درباره محیطی که با آن در تعامل است چیزهای جدید بیاموزد . در انتها بعد از چندین دوره کاوش عامل ممکن است انتخابی انجام دهد که قبلاً کاوش شده است که exploitation نام دارد .در یادگیری تقویتی همیشه یک بده بستان بین انتخاب یکی از اکشن های خوب قبلی یا انتخاب یک اکشن جدید وجود دارد که به exploration-exploitation dilemma معروف است .
فرایندهای تصمیمگیری مارکوف
مسایل یادگیری تقویتی به صورت ریاضی توسط این فریم ورک توصیف میشوند.MDP در واقع شکل توسعه داده شده زنجیره مارکوف است که دو عنصر پاداش و تصمیم گیری به آن اضافه شده است .کلمه مارکوف در اینجا به خصوصیت مارکف اشاره دارد (فرایندی که احتمال شرطی رویداد آینده فقط به آخرین رویداد موجود یعنی رویداد کنونی وابسته باشد نه به رویدادهای های گذشته) به عنوان مثال در بازی شطرنج حرکتی که میخواهیم انجام دهیم فقط به حالت کنونی سیستم وابسته است و نیازی نیست که نگران این موضوع باشی در حرکت قبلی یا حرکت های قبلی چه چیزی را انتخاب کرده ایم.