Ensemble learning معمولا برای گرفتن میانگین پیشبینی مدل های مختلف استفاده میشه . به زبان ساده این متد مثل استفاده کردن از پیشبینی مدل های کوچک بر روی بخش های مختلف فضای ورودی هست .
از این متد عمدتا در مسابقاتی مثل kaggle استفاده میشه ، جایی که شرکت کنندگان فقط دقت خروجی یا accuracy براشون مهم هست و نه پیچیدگی مدل یا سرعت !
تقریبا تمام نفرات برتر در مسابقات kaggle از ترکیب طبقه بندهای مختلف که شامل شبکه های عصبی مختلف با پارامتر های متفاوت هست استفاده میکنند .
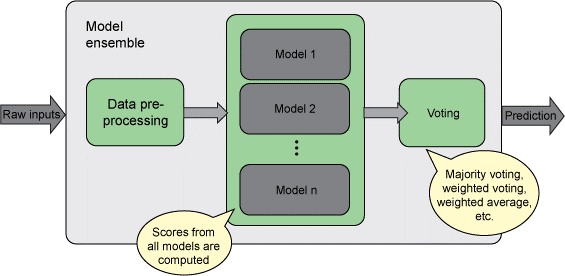
یک مثال این مقاله هست که SOTA تشخیصی حالات چهره هست .
کاری که نویسندگان انجام دادن آموزش سه شبکه عصبی بود که هر سه شبکه ساختاری مشابه benchmark های معروف
مثل reset,VGG,googlenet دارند.
در نهایت با میانگین گیری بر روی سه شبکه نتایج رو ۳ درصد بهبود داده .
این روش همیشه کار میکنه و نتایج خروجی رو ۲ تا سه درصد بهبود میده .
دلیل اینکه این روش کار میکنه به این خاطر هست « اگر یک کلاسیفایر در مورد یک نمونه آزمایش خروجی اشتباهی تولید میکنه میتونه به دو دلیل عمده باشه یا bias یا variance.
در مورد برنامه های کاربردی این روش تقریبا جایگاهی نداره .
ترکیب مدل های مختلف هر چند باعث افزایش دقت نهایی میشود،اما ما نمیتونیم بر روی یک مدل برای پیش بینی خروجی تکیه کنیم، از طرفی آموزش چندین مدل مختلف طاقت فرسا است مخصوصا اگر مدل شما عمیق، حجم داده ها زیاد و توان پردازشی سیستم شما پایین باشه
یک نکته وجود داره وقتی شما مدلی رو آموزش میدین شبکه شما یک نقطه مینیمم رو پیدا میکنه اما فضای جستجو بسیار عظیمه به صورتی که اگه مجددا مدل رو آموزش بدین شبکه نقطه دیگری رو به عنوان مینیمم انتخاب میکنه
هر کدام از این نقاط دارای نرخ خطای مشابهی هستند اما خطاهایی که توسط آنها تولید میشود دارای میژگی های متفاوتی میباشند.
Snapshot Ensembles: Train 1, get M for free
به این صورت که مدل رو آموزش میدین ،وقتی که به یک نقطه بهینه رسید از مدل یه کپی میگیرید نرخ یادگیری رو تغییر میدین ، مدل از اون نقطه بهینه خارج میشه و مجددا این کار رو تکرار میکنید در نهایت از کپی هایی که دارید میانگین میگیرید
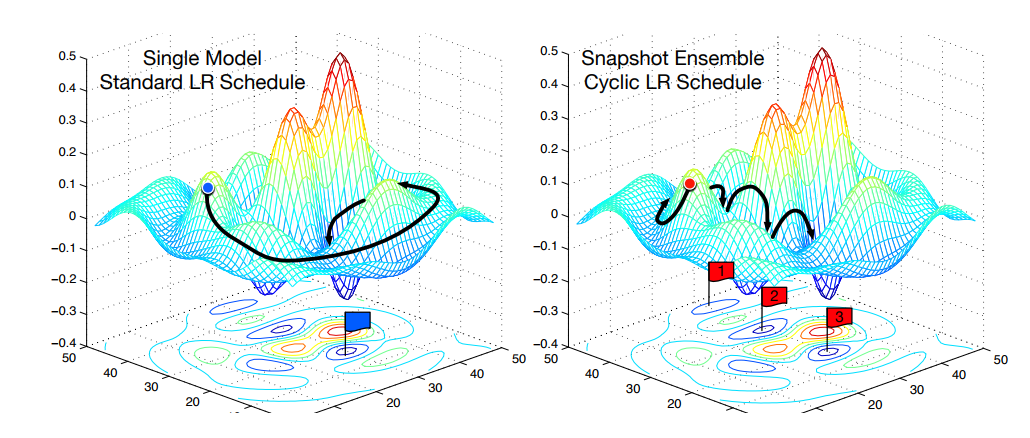
این روش همانند ترکیب چند مدلی باعث افزایش دقت خروجی خواهد شد
البته روش های متفاوتی هست که قبلاً در این لینک توضیح دادم