هنگامی که یک شبکه عصبی رو آمورش میدید یکی از تکنیک هایی که باعث بالا رفتن سرعت آموزش شبکه میشه نرمال سازی داده های ورودی هست.
پیش پردازش دادهها نقش مهمی در سایر الگوریتم های یادگیری عمیق بازی میکنه. در عمل متد هایی که از سایر الگوریتم های پیش پردازش داده ها مانند نرمال سازی استفاده میکنند خیلی بهتر عمل میکنند اگر چه انتخاب پارامتر های سودمند برای پیش پردازش داده ها با توجه به نوع داده متفاوت هست و به صورت تجربی بدست میاد .
تفریق میانگین
تفریق میانگین رایج ترین نوع پیش پردازش دادهاست. همانطور که از نام پیداست این عملیات شامل کسر میانگین داده ها از سایر نمونه های آموزشی هست .
نرمال سازی
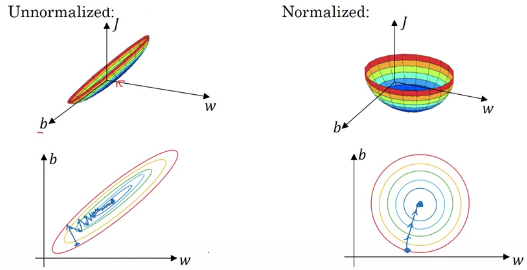
نرمال سازی به نرمال سازی ابعاد داده ها اشاره داره بطوریکه داده ها تقریبا در یک مقیاس مشابه قرار میگیرند . دو نوع رایج نرمال سازی داده وجود داره. یک تقسیم هر بعد از داده بر انحراف معیار آن بعد از انتقال مرکز داده ها به صفر ، دو پیش پردازش داده ها به صورتی که مینیمم و ماکسیمم داده ها در هر بعد در بازه ۱ و -۱ است . این عملیات در صورتی مفید است که ویژگی ها دارای مقیاس متفاوتی هستند . در مورد عکس ها ، چون مقادیر پیکسل ها در بازه ۰ تا ۲۵۵ است اعمال این عملیات لزوما اجباری نیست .
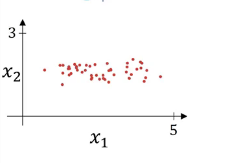
فرض کنید ویژگی های ورودی ما دو ویژگی x1 و x2 هستند:
نرم مال سازی ورودی شامل دو مرحله هست : مرحله اول subtract mean
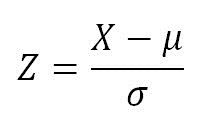
که ميو
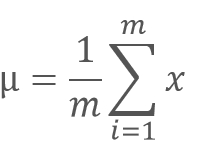
ميو از میانگین تمامی نمونه های آموزشی(عکس ها) محاسبه میشه. نتیجه این عملیات باعث میشه که داده ها zero-center شوند:
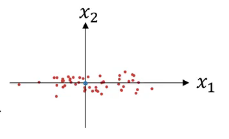
همانطور که در شکل بالا نمایش داده شده x1 واریانس بیشتری نسبت به x2 داره به همین دلیل واریانس رو هم در ادامه نرمال میکنیم.
در عمل شما عملیات مشابهی برای داده های آموزش انجام میدین و برای نرمال سازی داده های آموزش از میو و واریانسی که قبلا توسط داده های آموزش محاسبه شده استفاده میکنید، چون میخواهیم هم داده های آموزش و هم آزمایش از transformation مشابهی استفاده کنند.
اگر داده هاتون رو در مرحله اول نرمال کنید ویژگی ها همه در یک مقیاس مشابه قرار میگیرند این خصوصیت باعث میشه که عملیات بهینه سازی سریعتر و آسانتر انجام شوند.
من همیشه قبل از تغدیه مدلم بوسیله داده اونها رو توسط تابعی در numpy پیش پردازش میکنم. گاهی اوقات نیازه که PCA و Whitening رو نیز اعمال کنم. در این عملیات ابتدا داده ها به مرکز صفر انتقال داده میشوند و سپس ماتریس کواریانس داده ها محاسبه میشود ، این ماتریس همبستگی ساختار داده ها را نشان میده
روش Principal Component Analysis بر اساس تعیین مولفه های اصلی یا (Principal Component ها) در داده ها این کار را انجام میده. مولفه های اصلی در حقیقت همان بردار ویژه های ماتریس کوواریانس داده ها هستند.
بیشترین واریانس داد ها در راستایی قرار دارده که بردار ویژه ی متناظر با بزرگترین مقدار ویژه در آن راستا قرار دارد. به همین ترتیب هر چقدر مقدار ویژه کوچکتر شود واریانس داده ها در راستای بردار ویژه متناظر با آن کمتر می شه.
اما فریم ورکی مثل keras این کار رو میتونه به صورت خودکار با معرفی چند تا پارامتر انجام بده