سلام
علاوه بر توضیحاتی که Alister عزیز زحمتش رو کشید باید گفت که از این تکنیک عموما برای کاهش سربار پردازشی و تعداد پارامترهای قابل یادگیری استفاده میشه.
بعنوان مثال در تصویر زیر محاسبات مربوط به اعمال یک فیلتر (یک لایه) رو در حالت معمول شاهد هستیم. میبینیم ک همین عملیات ساده 153 هزار پارامتر و 120 میلیون عملیات اعشاری رو موجب میشه.
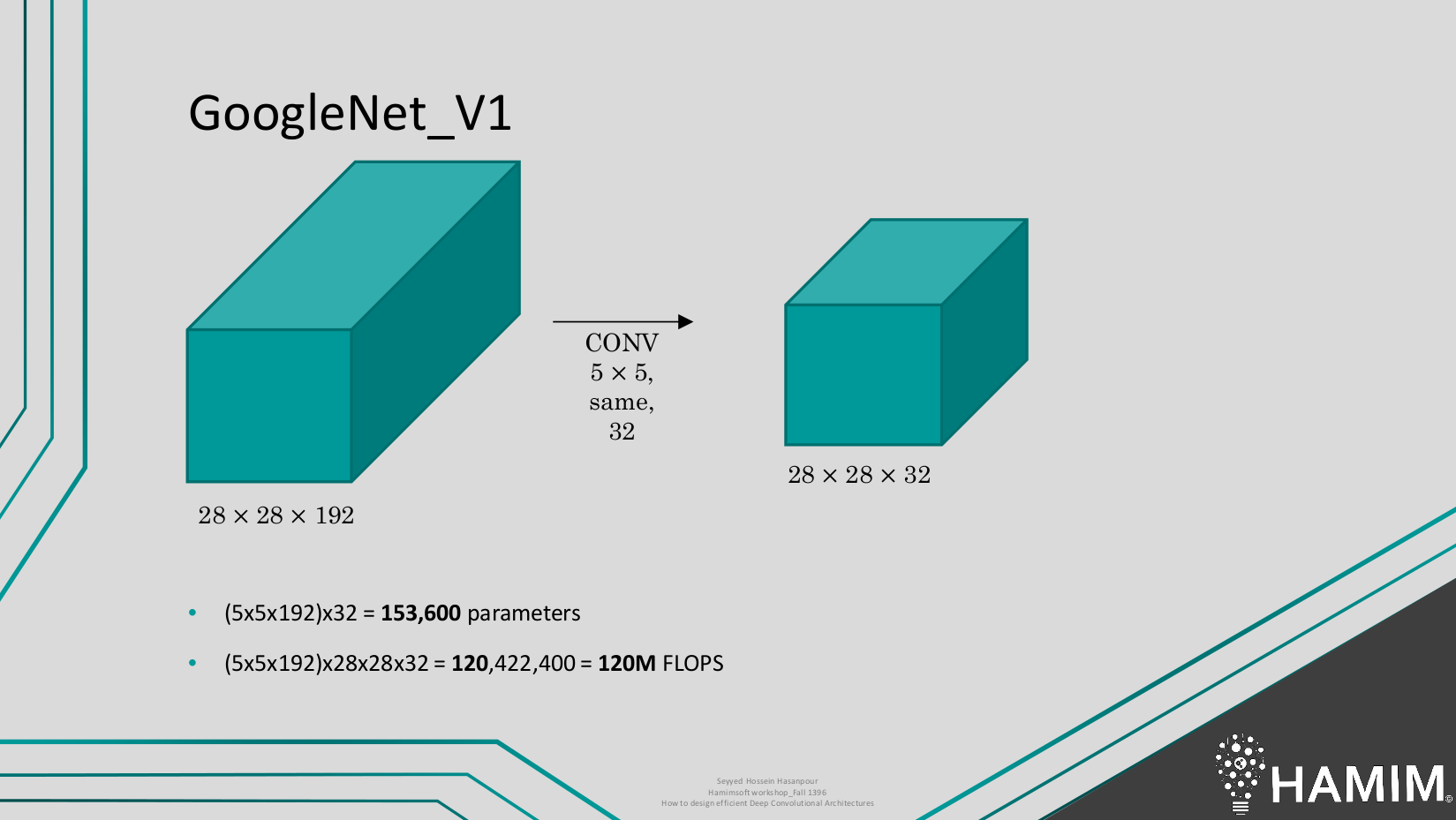
حالا با استفاده از یک لایه ۱در۱ ببینیم چقدر در سربار پردازشی و تعداد پارامترهای قابل یادگیری شاهد کاهش هستیم :

میبینیم با استفاده از این تکنیک تعداد پارامترهای قابل یادگیری کاهش بسیار چشم گیری داشتند از ۱۵۳ هزار به ۱۵ هزار پارامتر کاهش پیدا کردند. به همین شکل میبینیم که تعداد عملیات اعشاری مورد نیاز هم بشدت کاهش رو تجربه میکنه و از ۱۲۰ میلیون پارامتر به ۱۲ میلیون پارامتر میرسه.
وجود همچین مکانیزمی برای معماری های مبتنی بر NIN مثل سری معماری های گوگل نت و انواع مختلف inception یک ضرورت بحساب میاد چرا که بدون استفاده از تکنیک های اینچنینی استفاده عملی از اون معماری ها قابل تصور نیست یا حداقل به این صورت و فرم فعلی اونها. همچنین معماری های بسیار عمیقی مثل ResNetو نسخه های مبتنی بر اون هم نیازمند مکانیزمی جهت جلوگیری از افزایش شدید تعداد پارامتر با افزایش عمق هستند به همین دلیل در این نوع معماری ها هم از این دست تکنیک ها مشاهده میکنید.
یک نکته خیلی مهم در رابطه با این تکنیک ها این هست که صرف کاهش سربار پردازشی و تعداد پارامتر نباید دلایلی برای استفاده بی رویه از این روشها باشه. برای کاهش سربار هار پردازشی روشهای مختلفی وجود داره و هر روش تاثیرات مختلفی رو روی معماری شما و قدرت تمایز شبکه میزاره. از طرف دیگه شیوه طراحی معماری هم باعث میشه شما بیشتر به طرف استفاده از بعضی از این تکنیک ها سوق پیدا کنید. الزاما چیز خوبی نیست. بنابر این لازمه دقت کافی رو داشته باشید.
تصاویر بالا بخشی از پرزنتیشن ما در سال قبل بود که به این موارد پرداختیم .
میتونید فایل اصلی رو از اینجا دانلود کنید و مابقی اسلایدها رو مطالعه کنید.
همینطور مطالعه این مقاله هم پیشنهاد میشه اگر قبلا مطالعه نکردید:
Towards Principled Design of Deep Convolutional Networks
ضمنا اسم تکنیکی که بهش اشاره کردید به bottleneck معروف هست. در فایل پرزنتیشن به بخش رزنت مراجعه کنید باید توضیحاتی باشه.علاوه بر مقاله ای که علی آقای عزیز معرفی کردن مقاله inceptionv3 یا rethinking inception و همینطور مقاله resnet رو مطالعه کنید خوبه. علاوه بر اینها با توجه به عملیاتی که اینجا دیدید خودتون حالات دیگه رو تست کنید تا بیشتر پی ببرید چرا این تکنیک بیشتر مورد استفاده قرار میگیره.