با سلام
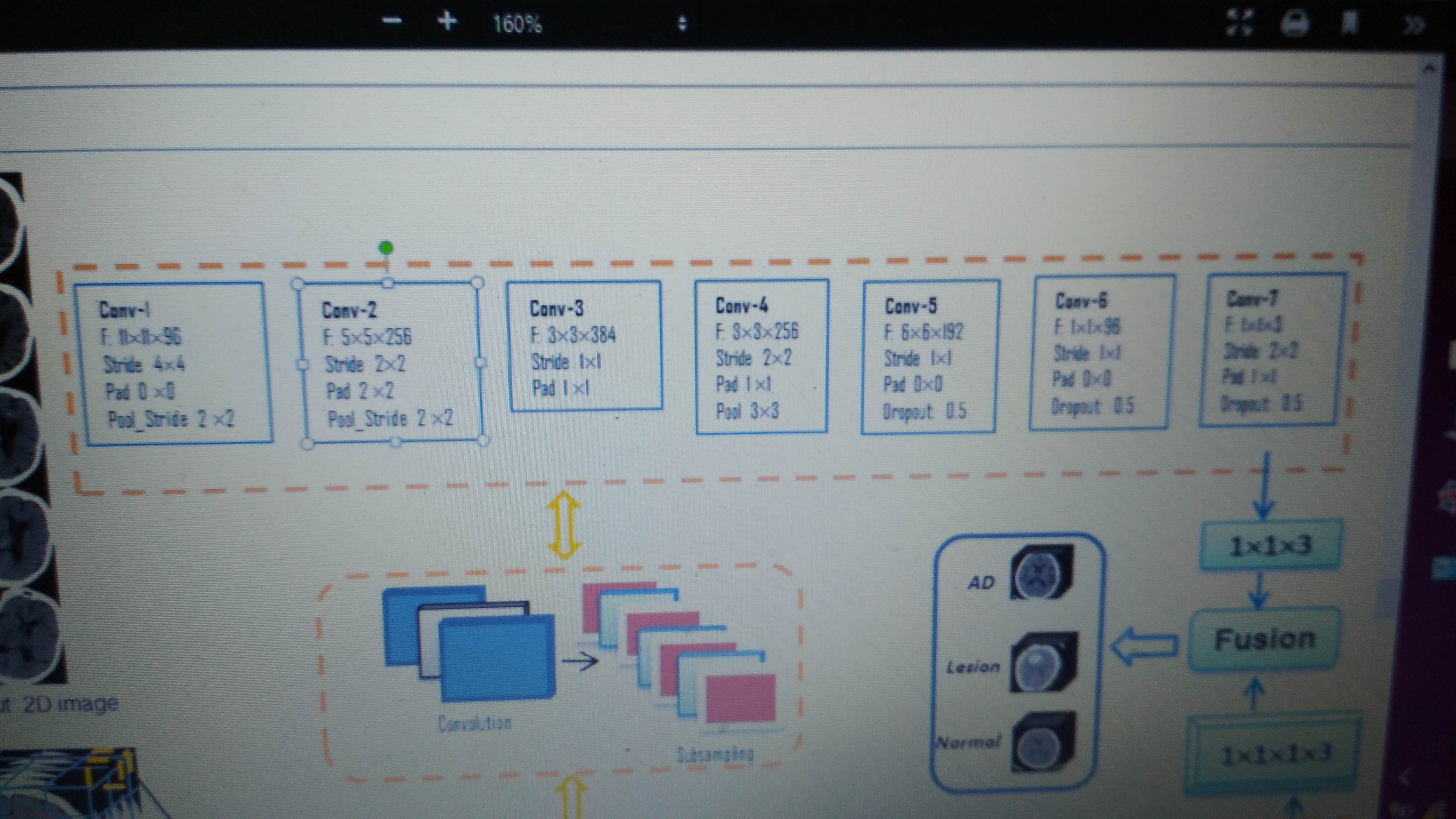
من از یک شبکه کانوولوشن 7 لایه برای یادگیری روی یک دیتاست پزشکی استفاده کردم که تعداد تصویر 4212 تصویر 200*200 و سه کلاسه است .مشکل من اینه که دقت زمان یادگیری در حدود 0.5 است و روند افزایش به شدت کمه تا جایی که بعد از 10 تکرار تابت میشه.دقت روی ولیدیشن که کلن ثابت .ولی مقدار loss چه در زمان ترینینگ و چه در ولیدیشن تغییر میکنه ولی خیلی کم.نکته ای که وجود داره اینه که در ابتدای یک دور که تعداد بچ ها تغییر میکنن دقت بالا میره ولی وقتی میگذره روند رشدش رو به پایین میشه و .نرخ یادگیری رو تغییر دادم و تقریبا از همه روش ها استفاده کردم ولی فایده ای نداشت.از dropout هم استفاده کردم.خود مقاله با این لایه ها در حدود 0.84 دقت داشته روی داده های تست.معماری هم به شکل زیر:
model = Sequential()
model.add(Convolution2D(96, (11, 11), subsample=(4, 4),activation='relu',padding="valid",kernel_initializer='random_normal', input_shape=(200,200,1),data_format="channels_last"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(ZeroPadding2D(padding=(2, 2)))
model.add(Convolution2D(256,( 5, 5),subsample=(2, 2), activation='relu',padding="same"))
model.add(Convolution2D(48,( 1, 1),
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(ZeroPadding2D(padding=(1, 1)))
model.add(Convolution2D(384,( 3, 3),subsample=(1, 1), activation='relu',padding="same"))
model.add(Convolution2D(256, (3, 3),subsample=(2, 2), activation='relu',padding="same"))
model.add(MaxPooling2D(pool_size=(3,3)))
model.add(Convolution2D(192,( 6, 6),subsample=(1, 1), activation='relu',padding="same"))
#model.add(normalization.BatchNormalization())
model.add(Dropout(0.25))
model.add(Convolution2D(96,( 1, 1),subsample=(1, 1), activation='relu',padding="valid"))
#model.add(normalization.BatchNormalization())
model.add(Dropout(0.25))
model.add(ZeroPadding2D(padding=(1, 1)))
model.add(Convolution2D(3,( 1, 1),subsample=(2, 2), activation='relu',padding="same"))
model.add(Dropout(0.25))
#model.add(MaxPooling2D(pool_size=(7, 7),strides=1, padding='same'))
model.add(Flatten())
model.add(Dense(3,activation='softmax'))
sgd = SGD(lr=0.0001, decay=1e-6, momentum=1, nesterov=True)
model.compile(loss='categorical_crossentropy
optimizer=sgd,
metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch,
show_accuracy=True, verbose=1, validation_data=(X_test, Y_test))
history=model.fit(X_train, Y_train,
batch_size=25,shuffle=True, nb_epoch=15, verbose=1,validation_data=(X_test, Y_test))
.
- 2695/2695 [==============================] - **122s 45ms/step - loss:
1.0979 - acc: 0.5340 - val_loss: 1.0972 - val_acc: 0.5386 Epoch 2/15 2695/2695 [==============================] - 133s 49ms/step - loss:
1.0966 - acc: 0.5343 - val_loss: 1.0959 - val_acc: 0.5386 Epoch 3/15 2695/2695 [==============================] - 132s 49ms/step - loss:
1.0953 - acc: 0.5343 - val_loss: 1.0945 - val_acc: 0.5386 Epoch 4/15 2695/2695 [==============================] - 127s 47ms/step - loss:
1.0940 - acc: 0.5343 - val_loss: 1.0932 - val_acc: 0.5386
--![][1]------------------------------------------------------------------